
Ai Breakdown Or Takeaways From The 78 Page Llama 2 Paper Deepgram
Open Foundation and Fine-Tuned Chat Models In this work we develop and release Llama 2 a collection of pretrained and fine-tuned. Llama-2 isnt a single model but rather a collection of four models The only difference between each of these models is the number of. The LLaMA-2 paper describes the architecture in good detail to help data scientists recreate fine. Similar to LLaMA-2 with 40 more data only public data better data cleaning and larger context. Llama 2 is a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters..
This chatbot is created using the open-source Llama 2 LLM model from Meta. The app includes session chat history and provides an option to select multiple LLaMA2 API endpoints on Replicate. Do you want to build a medical chatbot using the latest language models..
Llama-2-7b-chat like 369 Running on zero Loading Discover amazing ML apps made by the community. Llama 2 is a family of state-of-the-art open-access large language models released by Meta today and were excited to fully support the launch with comprehensive integration. Llama 2 is here - get it on Hugging Face a blog post about Llama 2 and how to use it with Transformers and PEFT LLaMA 2 - Every Resource you need a compilation of relevant resources to. Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters This is the repository for the 7B pretrained model. In this section we look at the tools available in the Hugging Face ecosystem to efficiently train Llama 2 on simple hardware and show how to fine-tune the 7B version of Llama 2 on a single..
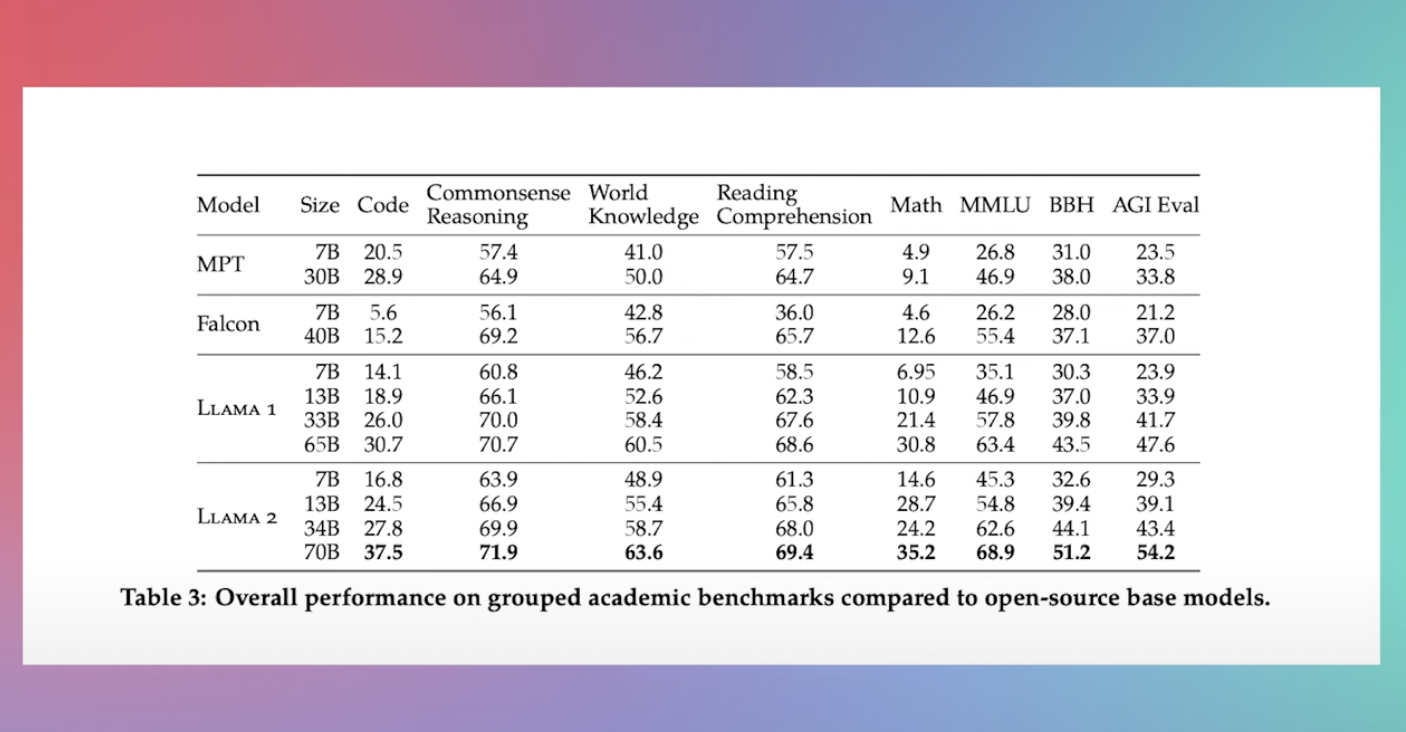
However there remains a clear performance gap between LLaMA 2 70B and the behemoth that is GPT-4 especially in specific tasks like the HumanEval coding benchmark. 817 This means we should use. A bigger size of the model isnt always an advantage Sometimes its precisely the opposite and thats the case here. Extremely low accuracy due to pronounced ordering bias For best factual summarization close to human. Llama-2-70b is a very good language model at creating text that is true and accurate It is almost as good as GPT-4 and much better than GPT-35-turbo..

Ai Breakdown Or Takeaways From The 78 Page Llama 2 Paper Deepgram


Komentar